GraphQL quick start
learn:getting_started/gql_quick_start.adoc

GraphQL is an open source data query and manipulation language that provides declarative schema definitions and a composable query syntax. By design, GraphQL eliminates over- and under-fetching of relational data, which minimizes network and memory use for clients.
Resources
This tutorial, and other GraphQL topics covered within this documentation, provides details of the Fauna GraphQL API. For more general information about GraphQL, training, or the specification itself, see these resources:
GraphQL tutorial
This tutorial demonstrates how to get started with GraphQL, including designing an initial schema, importing that schema into Fauna, adding a few documents, and then running a GraphQL query to retrieve those documents. Start to finish, these steps should only take a few minutes to complete.
The steps:
-
Visit https://dashboard.fauna.com/ in your web browser, and log in.
-
Let’s create a new database to hold our GraphQL data. Any database would work, but this keeps your GraphQL experiments separate.
-
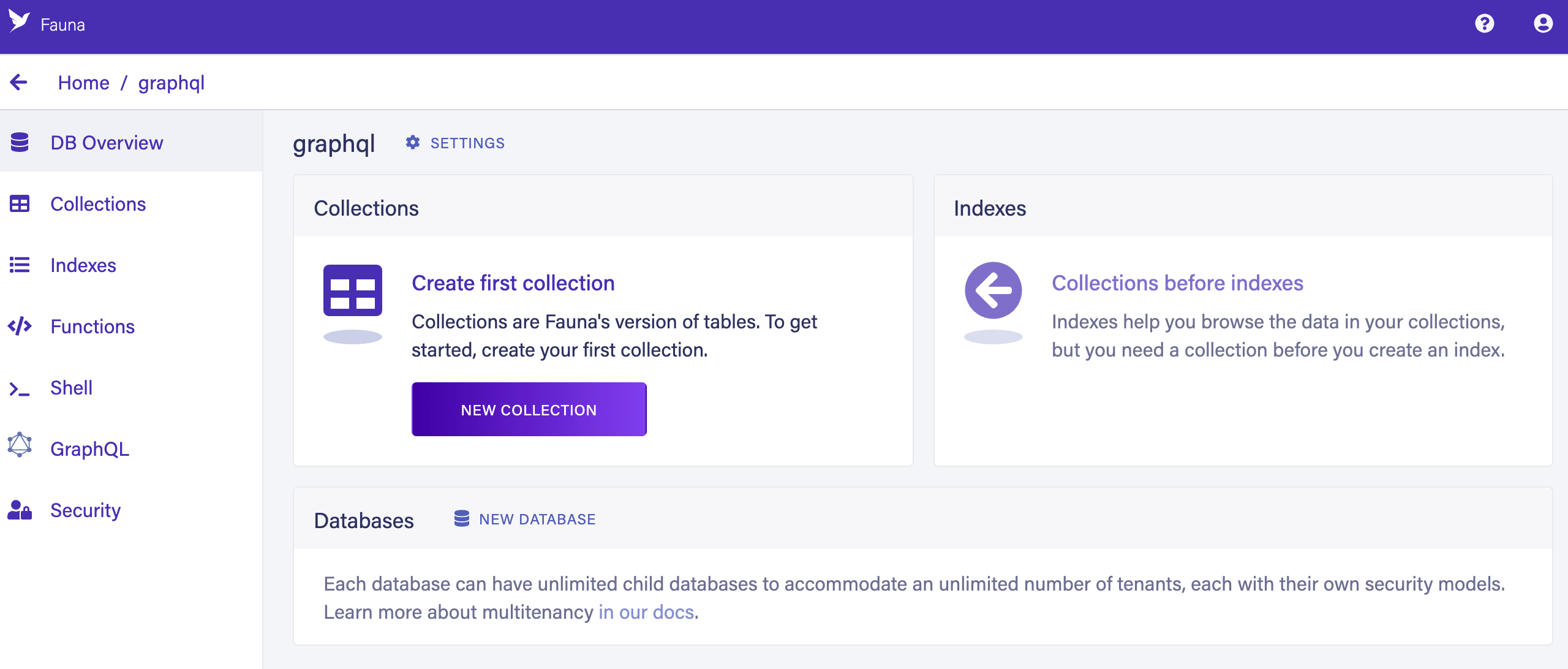
Click CREATE DATABASE.
-
Enter
graphqlinto the Database Name field. -
Select
Classicfrom the REGION GROUP dropdown menu. -
Press Return (or click SAVE).
-
-
A GraphQL schema defines the "shape" of the data that can be managed and queried, including all of the fields and their types. We are starting with a very basic schema for a "todo" list, where each todo item is just a title and a flag to indicate whether the item is complete or not. The schema also defines the kinds of queries that we want to run.
Create a file called
schema.gqlcontaining the following content: -
Before we can perform any GraphQL queries, we need to import the schema into Fauna. Once we do so, the Fauna GraphQL API automatically creates the necessary classes and indexes to support the schema.
Click GRAPHQL in the left sidebar.
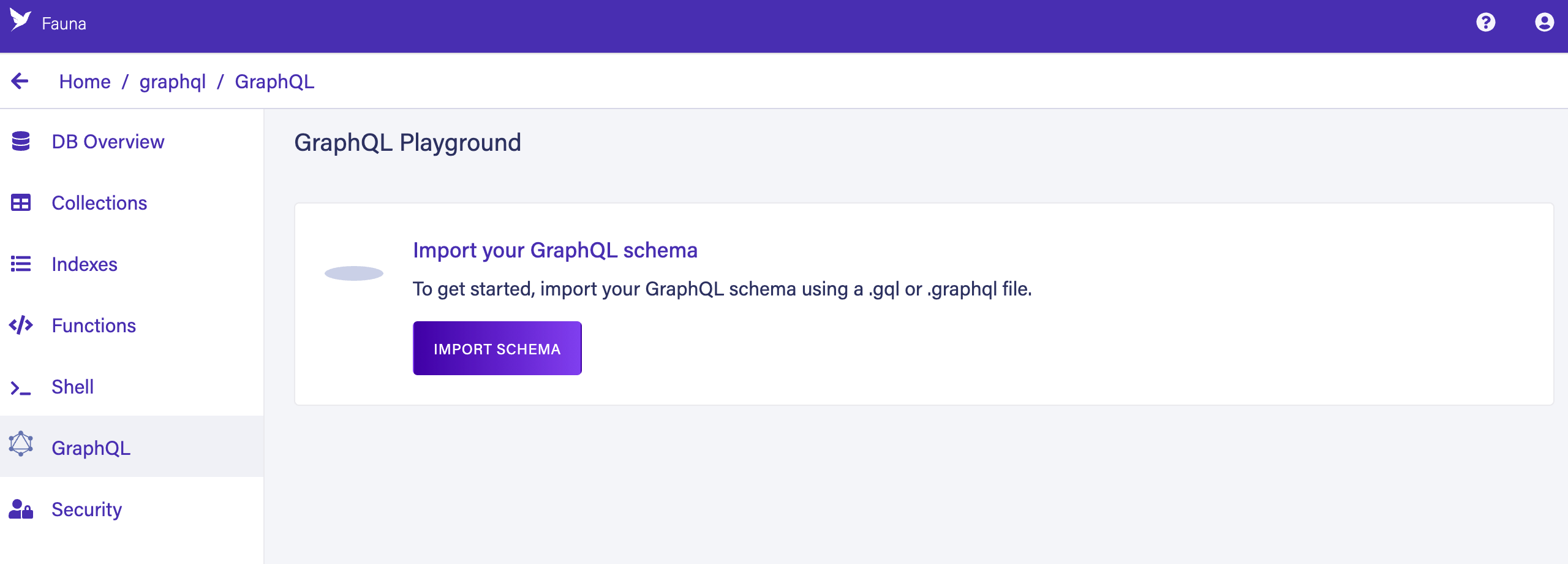
Click IMPORT SCHEMA, which opens your browser’s file selector. Select the
schema.gqlfile, and click the file selector’s OPEN button. The GraphQL Playground screen is displayed: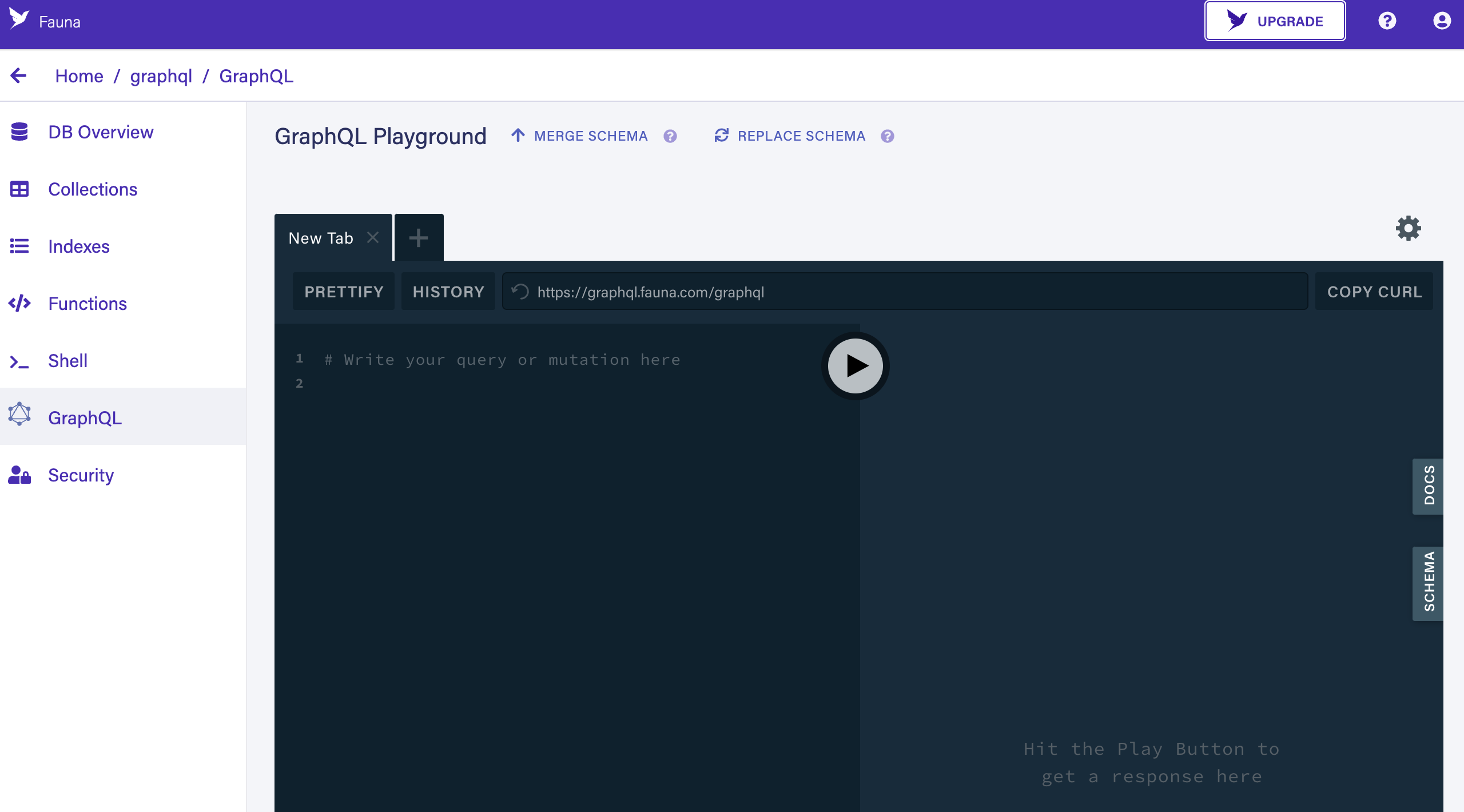
-
Even though our schema has been imported, there are no documents yet. Let’s create one. Copy the following GraphQL mutation query into the left panel of the GraphQL Playground screen:
graphqlCopied!mutation CreateATodo { createTodo(data: { title: "Build an awesome app!" completed: false }) { title completed } }Click the PLAY button (the circle with the right-facing triangle). The query should execute and the response should appear in the right panel:
{ "data": { "createTodo": { "title": "Build an awesome app!", "completed": false } } }The GraphQL Playground screen should now look like this:
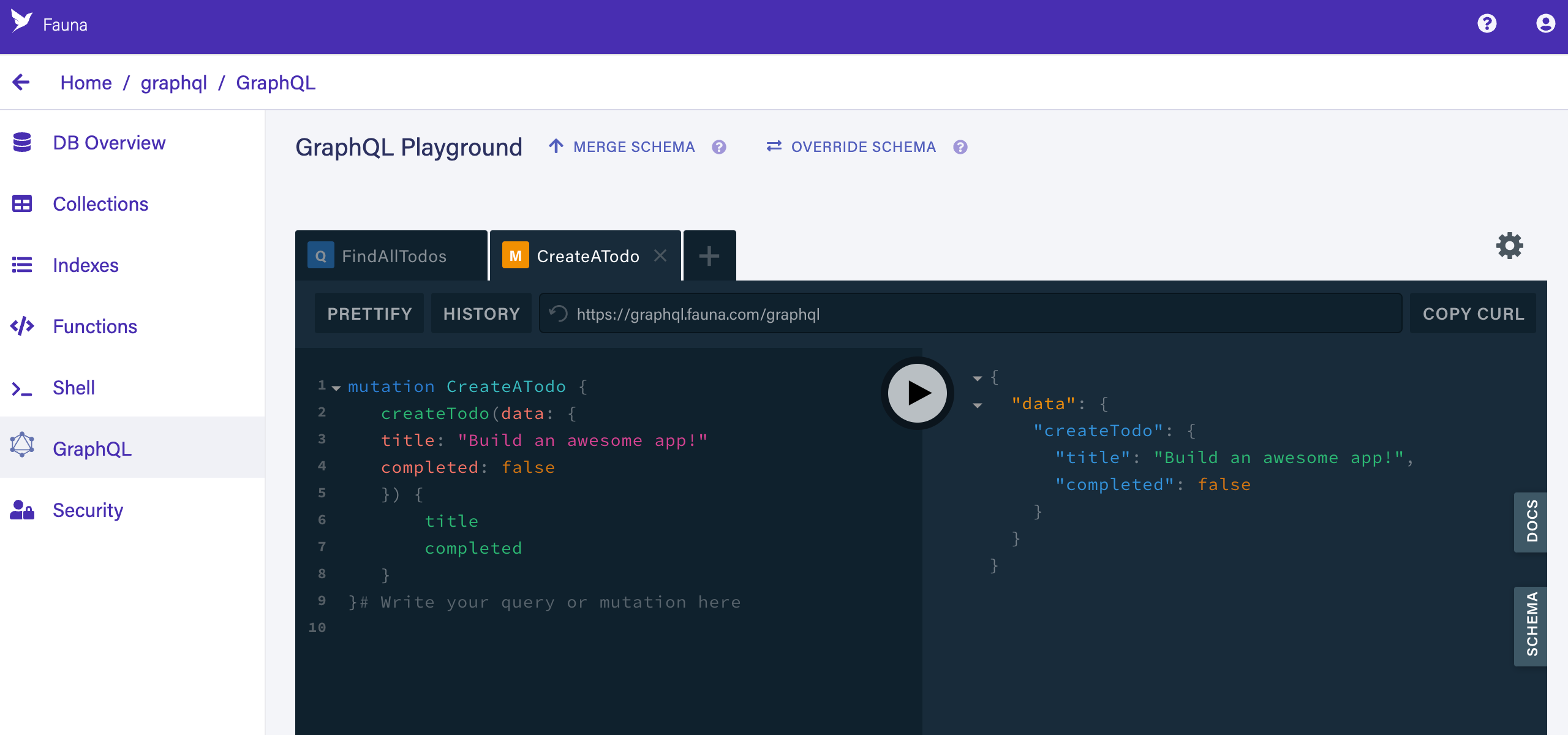
-
Now that we have a document that can be fetched, let’s run a query to fetch all documents. Copy the following GraphQL fetch query:
graphqlCopied!query FindAllTodos { allTodos { data { _id title completed } } }Then click the "new tab"
+button in the GraphQL Playground screen (at the top left, just right of theCreateATodotab). Then paste the query into the left panel, and click the PLAY button. The query should execute and the response should appear in the right panel:{ "data": { "allTodos": { "data": [ { "_id": "235276560024732167", "title": "Build an awesome app!", "completed": false } ] } } }GraphQL Playground should now look like this:
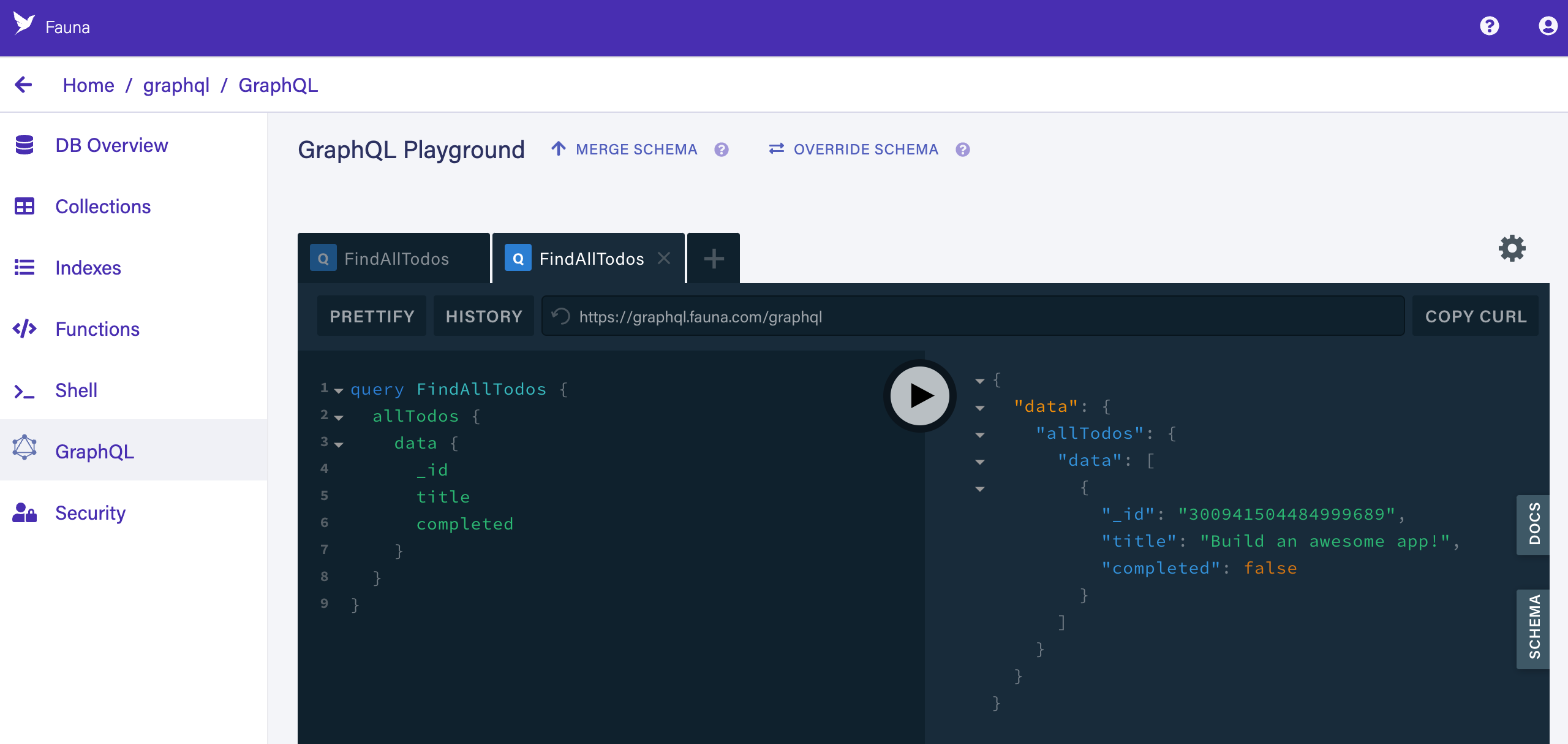
While GraphQL famously solves the over-fetching and under-fetching of traditional REST APIs, it sometimes causes another serious problem: too many round trips to the server, AKA the notorious "n+1 problem". Typically, there are two approaches to solve this:
-
The first is query batching/caching with a data loader, but such tools introduce complexity and don’t solve the entire problem. You still end up with more than one round trip to the server.
-
The second is to generate one query from each GraphQL query, but this sometimes results in a monster join that can choke traditional SQL databases. Instead of relying on joins, Fauna uses a strategy more akin to what graph databases call index-free adjacency. By nesting Map/Get queries, FQL maps perfectly on the execution plan of a GraphQL query, efficiently walking down the GraphQL tree and retrieving nested documents.
In other words, any given query you send to the GraphQL API always incurs only one single request to the database, and does so efficiently. For a more in-depth explanation, with examples, see our blog post.
Conclusion
You have now seen how to prepare Fauna for GraphQL queries, how to create and import a GraphQL schema, how to use the GraphQL Playground screen to create and query data. You are now ready to continue your GraphQL journey!
Is this article helpful?
Tell Fauna how the article can be improved:
Visit Fauna's forums
or email docs@fauna.com
Thank you for your feedback!