Rethinking the Serverless App
The gold standard, for example, applications that feature a specific technology, is a todo app — because they are simple. Any database can serve a very simple application and shine.
And that is exactly why this app is different. To truly want to show how Fauna excels for real-world applications, we need to build something more advanced.
Introducing Fwitter
This serverless database application is called "Fwitter". When you clone the Fwitter repository and start digging around, you might notice a plethora of well-commented example queries not covered in this article. This article covers just enough to get you up and running. Future tutorials will use Fwitter as the basis for more advanced features and topics.
But, for now, here’s a basic rundown of what we are going to cover here:
We build these features without having to configure operations or set up servers for your database. Since Fauna is scalable and distributed out-of-the-box, all of the operational concerns for running a geographically-distributed, always-consistent database are already taken care of.
Let’s dive in!
Modeling the data
Before we can show how Fauna excels at relations, we need to cover the types of relations in our application’s data model.
Fauna’s data entities are stored in documents, which are then stored in collections — like rows in tables. For example, each user’s details are represented by a User document stored in a Users collection. And we eventually plan to support both single sign-on and password-based login methods for a single user, each of which would be represented as an Account document in an Accounts collection.
At this point, one user has one account, so it doesn’t matter which entity stores the reference (i.e., the user ID). We could have stored the user ID in either the Account or the User document in a one-to-one relation:
![]()
However, since one User will eventually have multiple Accounts (or authentication methods), our data model uses a one-to-many model:

In a one-to-many relation between Users and Accounts, each Account points to only one user, so it makes sense to store the User reference on the Account:

The application also has many-to-many relations, like the relations between Fweets and Users, because of the complex ways users interact with each other via likes, comments, and refweets:

Further, we use a third collection, Fweetstats, to store information about the interaction between a User and a Fweet:

Fweetstats’ data helps us determine, for example, whether or not to color the icons indicating to the user that he has already liked, commented, or refweeted a Fweet. It also helps us determine what clicking on the heart means: unlike or like:
![]()
The final model for the application looks like this:

Fweets are at the center of the model because they contain the most important data of the Fweet, such as the information about the message, the number of likes, refweets, and comments. Fauna stores this data in a JSON format that looks like this:
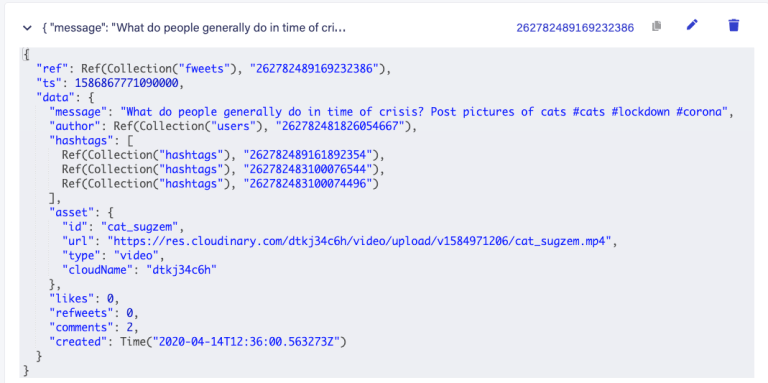
As shown in the model and this example JSON, hashtags are stored as a list of references. If we wanted to, we could have stored the complete hashtag JSON here, and that is the preferred solution in more limited document-based databases that lack relations. However, that would mean that our hashtags would be duplicated everywhere (as they are in more limited databases), and it would be more difficult to search for hashtags and/or retrieve Fweets for a specific hashtag:
Note that a Fweet does not contain a link to Comments, but the Comments collection contains a reference to the Fweet. That’s because one Comment belongs to one Fweet, but a Fweet can have many comments — similar to the one-to-many relation between Users and Accounts.
Finally, there is a FollowerStats collection which basically saves information about how much users interact with each other to personalize their respective feeds. This guide does not cover every application feature, but you can experiment with the queries in the Fwitter repository as we continue to extend this guide.
Hopefully, you’re starting to see why we chose something more complex than a ToDo app. It’s already becoming apparent that implementing such an application without relations would be a serious brain-breaker.
Now, if you haven’t already done so from the Fwitter repository, it’s finally time to get our project running locally!
Setup the project
To set up the project, go to the Fauna Dashboard and sign up. Once you are in the Dashboard, click New Database, fill in a name, and click Save. You should now be on the "Overview" page of your new database.
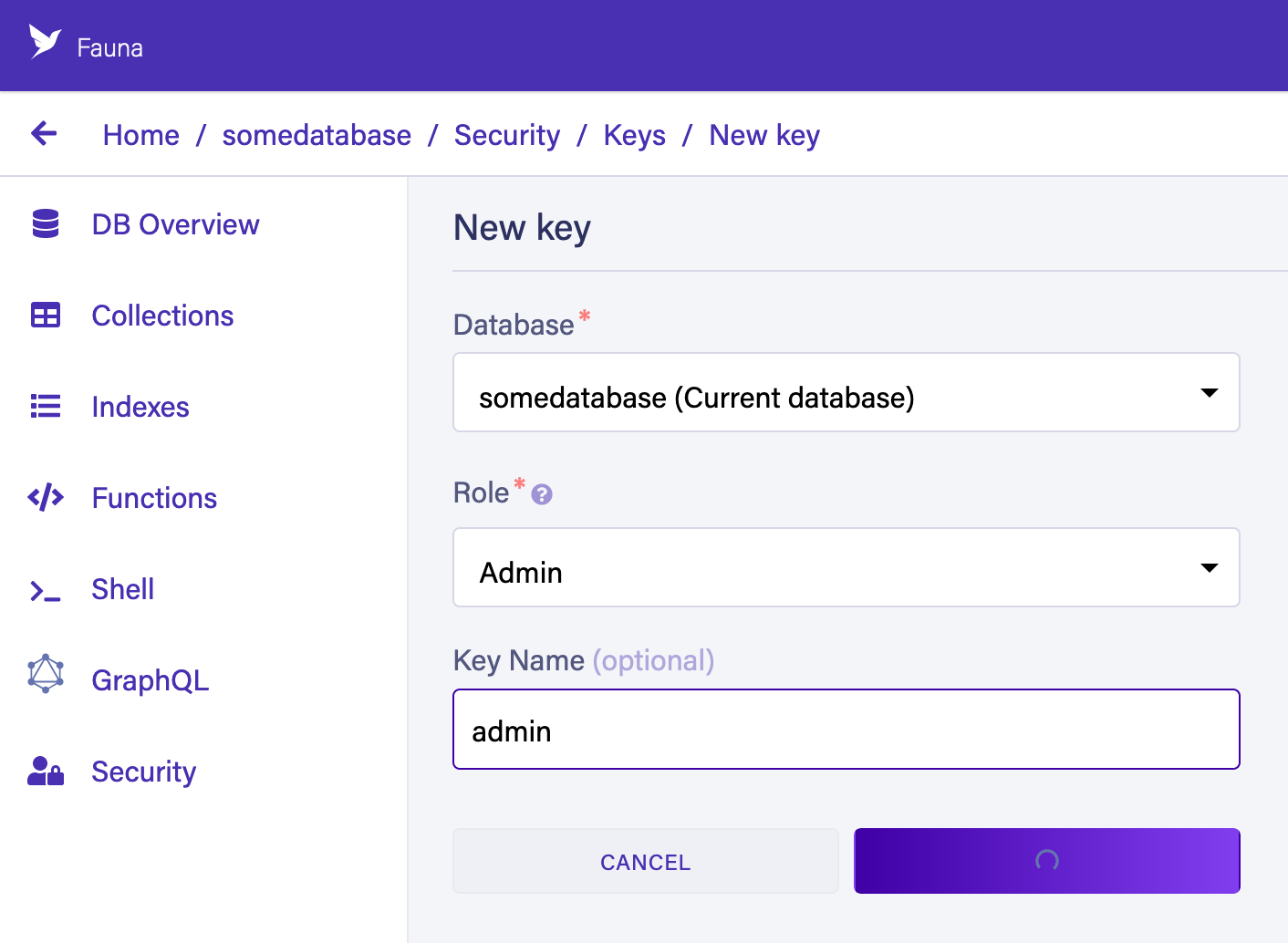
Next, we need a key that can be used in our setup scripts. Click Security in the left sidebar, then click the New key button.
In the "New key" form, the current database should already be selected. For the "Role" field, leave it as "Admin". Optionally, add a key name. Next, click Save and copy the key’s secret displayed on the next page. It is never displayed again.
Now that you have your database secret, clone the Fwitter repository and follow the
README. We have prepared a few scripts so you only have to run the
following commands to initialize your app, create all of the collections,
and populate your database. The scripts give you further instructions:
npm install
npm run setup (1)
npm run populate (2)
npm run start| 1 | This command creates all of the resources in your database. Provide
the admin key when the script asks for it. The setup script then
gives you another key with almost no permissions that you need to
place in your .env.local file, as the script suggests. |
| 2 | This script adds data to your database. |
After the script has completed, your .env.local file should contain
the bootstrap key that the script provided to you (not the admin key).
REACT_APP_LOCAL___BOOTSTRAP_FAUNADB_KEY=<bootstrap key>Creating the front end
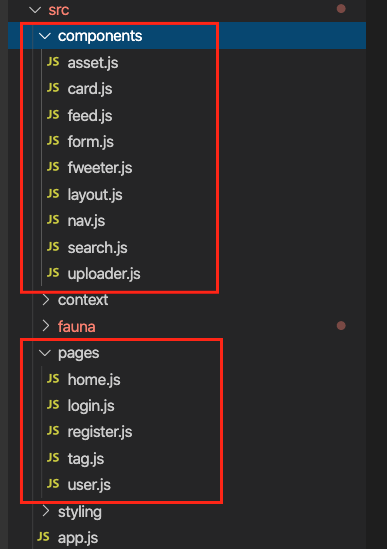
For the frontend, we used create-react-app to generate an application,
then divided the application into pages and components. Pages are
top-level components which have their own URLs. The Login and Register
pages speak for themselves. Home is the standard feed of Fweets from the
authors we follow; this is the page that we see when we log into our
account. And the User and Tag pages show the Fweets for a specific user
or tag in reverse chronological order.
We use React Router to direct to these pages depending on the URL, as
you can see in the src/app.js file:
<Router>
<SessionProvider value={{ state, dispatch }}>
<Layout>
<Switch>
<Route exact path="/accounts/login">
<Login />
</Route>
<Route exact path="/accounts/register">
<Register />
</Route>
<Route path="/users/:authorHandle" component={User} />
<Route path="/tags/:tag" component={Tag} />
<Route path="/">
<Home />
</Route>
</Switch>
</Layout>
</SessionProvider>
</Router>The only other thing to note in the above snippet is the SessionProvider, which is a React context to store the user’s information upon logging in. For more details, see the How to implement authentication section. For now, it’s enough to know that this gives us access to the Account (and thus User) information from each component.
Take a quick look at the home page `src/pages/home.js` to see how we use a combination of hooks to manage our data. The bulk of our application’s logic is implemented in Fauna queries which live in the `src/fauna/queries` folder.
All calls to the database originate from the frontend, then pass through the query-manager. We can secure the sensitive parts with Fauna’s ABAC security rules and User Defined Functions (UDF). Since Fauna behaves as a token-secured API, we do not have to worry about a limit on the number of connections as we would in traditional databases.
The Fauna JavaScript driver
Next, take a look at the `src/fauna/query-manager.js` file to see how we connect
Fauna to our application using Fauna’s JavaScript driver, which is
just a Node.js module that we installed with npm install. As with any
Node.js module, we import it into our application like so:
import faunadb from 'faunadb'And we create a client by providing a token:
this.client = new faunadb.Client({
secret: token || this.bootstrapToken
})We cover tokens a little more in the How to implement authentication section. For now, let’s create some data!
Creating data
The logic to create a new Fweet document can be found in the `src/fauna/queries/fweets.js` file. Fauna documents are just like JSON, and each Fweet follows the same basic structure:
const data = {
data: {
message: message,
likes: 0,
refweets: 0,
comments: 0,
created: Now()
}
}The Now function is used to insert the time of the query so that
the Fweets in a user’s feed can be sorted chronologically. Note that
Fauna automatically places timestamps on every database entity for
temporal querying. However, the Fauna timestamp represents the time
the document was last updated, not the time it was created, and the
document gets updated every time a Fweet is liked; for our intended
sorting order, we need the created time.
Next, we send this data to Fauna with the Create function. By
providing Create with the reference to the Fweets collection
using Collection('fweets'), we specify where the document needs to
exist.
const query = Create(Collection('fweets'), data )We can now wrap this query in a function that takes a message parameter
and executes it using client.query(), which sends the query to the
database for execution. Before that, we can combine as many FQL
functions as we want to construct our query:
function createFweet(message, hashtags) {
const data = …
const query = …
return client.query(query)
}Note that we have used plain old JavaScript variables to compose this query and, in essence, just called functions. Writing FQL is all about function composition; you construct queries by combining small functions into larger expressions. This functional approach has very strong advantages. It allows us to use native language features such as JavaScript variables to compose queries while also writing higher-order FQL functions that are protected from injection.
For example, in the following query, we add hashtags to the document
with a CreateHashtags() function that we’ve defined elsewhere using
FQL:
const data = {
data: {
// ...
hashtags: CreateHashtags(tags),
likes: 0,
// ...
}The way FQL works from within the driver’s host language (in this case,
JavaScript) is what makes FQL an eDSL (embedded domain-specific
language). Functions like CreateHashtags() behave just like a native
FQL function in that they are both just functions that take input. This
means that we can easily extend the language with our own functions,
like in this open source FQL
library from the Fauna community.
It’s also important to notice that we create two entities in two different collections, in one transaction. Thus, if/when things go wrong, there is no risk that the Fweet is created, but the Hashtags are not. In more technical terms, Fauna is transactional and consistent whether you run queries over multiple collections or not, a rare property in scalable, distributed databases.
Next, we need to add the author to the query. First, we can use the
CurrentIdentity function to return a reference to the currently
logged-in document. As discussed previously in the Modeling the data section,
that document is of the type Account and is separated from Users to
support SSO in a later phase.

Then, we need to wrap the CurrentIdentity function in a
Get call to access the full Account document and not just the
reference to it:
Get(CurrentIdentity())Finally, we wrap all of that in a Select call to select the
data.user field from the account document and add it to the data JSON.
const data = {
data: {
// ...
hashtags: CreateHashtags(tags),
author: Select(['data', 'user'], Get(CurrentIdentity())),
likes: 0,
// ...
}
}Now that we’ve constructed the query, let’s pull it all together and
call client.query(query) to execute it:
function createFweet(message, hashtags) {
const data = {
data: {
message: message,
likes: 0,
refweets: 0,
comments: 0,
author: Select(['data', 'user'], Get(CurrentIdentity())),
hashtags: CreateHashtags(tags),
created: Now()
}
}
const query = Create(Collection('fweets'), data )
return client.query(query)
}By using functional composition, you can easily combine all of your advanced logic in one query that can be executed in one transaction. Check out the file `src/fauna/queries/fweets.js` to see the final result, which takes even more advantage of function composition to add rate-limiting, etc.
Securing your data with UDFs and ABAC roles
The attentive reader likely has some thoughts about security by now. We are essentially creating queries in JavaScript and calling these queries from the frontend. What stops a malicious user from altering these queries?
Fauna provides two features that allow us to secure our data: Attribute-Based Access Control (ABAC) and User Defined Functions (UDF). With ABAC, we can control which collections or entities a specific key or token can access by writing Roles.
With UDFs, we can combine multiple FQL statements into a single callable
function by using the CreateFunction function:
CreateFunction({
name: 'create_fweet',
body: <your FQL statement>,
})Once the function is in the database as a UDF, where the application can’t alter it anymore, we then call this UDF from the front end:
client.query(
Call(Function('create_fweet'), message, hashTags)
)Because the query is now saved in the database (just like a stored procedure), malicious users can no longer manipulate it from the client.
One example of how UDFs can be used to secure a call is that we do not
pass in the author of the Fweet. The author of the Fweet is derived from
the CurrentIdentity function instead, which makes it impossible
for a user to write a Fweet on someone else’s behalf.
Of course, we still have to define that the user has access to call the
UDF. For that, we use a very simple ABAC role that defines a group of
role members and their privileges. This role is named logged_in_role,
its membership includes all of the documents in the Accounts collection,
and all of these members are granted the privilege of calling the
create_fweet UDF.
CreateRole(
name: 'logged_in_role',
privileges: [
{
resource: q.Function('create_fweet'),
actions: {
call: true
}
}
],
membership: [{ resource: Collection('accounts') }],
)We now know that these privileges are granted to an account, but how do
we become an Account? By using the Login function to authenticate
our users as explained in the next section.
How to implement authentication
We just defined a role that gives Accounts the permissions to call the
create_fweets function. But how do we "become" an Account?
First, we create a new Account document, storing credentials alongside any other data associated with the Account (in this case, the email address and the reference to the User):
return Create(Collection('accounts'), {
credentials: { password: password },
data: {
email: email,
user: Select(['ref'], Var('user'))
}
})
}We can then call Login on the Account reference, which retrieves
a token:
Login(
<Account reference>,
{ password: password }
)We use this token in the client to impersonate the Account. Since all
Accounts are members of the Account collection, this token fulfills the
membership requirement of the logged_in_role and is granted access to
call the create_fweet UDF. To bootstrap this whole process, we have two
very important roles:
-
bootstrap_role: can only call the
loginandregisterUDFs -
logged_in_role: can call other functions such as
create_fweet
The token you received when you ran the setup script is essentially a
key created with the bootstrap_role. A client is created with that
token in `src/fauna/query-manager.js`, which is only able to register or
log in. Once we log in, we use the new token returned from Login
to create a new Fauna client, which now grants access to other UDF
functions such as create_fweet. Logging out means we just revert to
the bootstrap token. You can see this process in `src/fauna/query-manager.js`,
along with more complex role examples in the `src/fauna/setup/roles.js` file.
How to implement the session in React
Previously, in the Creating the front end section, we mentioned the SessionProvider component. In React, providers belong to a React Context, which is a concept to facilitate data sharing between different components. This is ideal for data such as user information that you need everywhere in your application. By inserting the SessionProvider in the HTML early on, we made sure that each component would have access to it. Now, the only thing a component has to do to access the user details is import the context and use React’s "useContext" hook:
import SessionContext from '../context/session'
import React, { useContext } from 'react'
// In your component
const sessionContext = useContext(SessionContext)
const { user } = sessionContext.stateBut how does the user end up in the context? When we included the SessionProvider, we passed in a value consisting of the current state and a dispatch function:
const [state, dispatch] = React.useReducer(sessionReducer, { user: null })
// ...
<SessionProvider value={{ state, dispatch }}>The state is simply the current state, and the dispatch function is
called to modify the context. This dispatch function is actually the
core of the context since creating a context only involves calling
React.createContext(), which gives you access to a Provider and a
Consumer:
const SessionContext = React.createContext({})
export const SessionProvider = SessionContext.Provider
export const SessionConsumer = SessionContext.Consumer
export default SessionContextWe can see that the state and dispatch are extracted from something that React calls a "reducer" (using React.useReducer), so let’s write a reducer:
export const sessionReducer = (state, action) => {
switch (action.type) {
case 'login': {
return { user: action.data.user }
}
case 'register': {
return { user: action.data.user }
}
case 'logout': {
return { user: null }
}
default: {
throw new Error(`Unhandled action type: ${action.type}`)
}
}
}This is the logic that allows you to change the context. In essence, it receives an action and decides how to modify the context given that action. In our case, the action is simply a type with a string. We use this context to keep user information, which means that we call it on a successful log in with:
sessionContext.dispatch({ type: 'login', data: e })Retrieving data
We have shown how to add data. Now we still need to retrieve data. Getting the data of our Fwitter feed has many challenges. We need to:
-
Get fweets from people you follow in a specific order (taking time and popularity into account).
-
Get the author of the fweet to show his profile image and handle.
-
Get the statistics to show how many likes, refweets, and comments it has.
-
Get the comments to list those beneath the fweet.
-
Get info about whether you already liked, refweeted, or commented on this specific fweet.
-
If it’s a refweet, get the original fweet.
This kind of query fetches data from many different collections and
requires advanced indexing/sorting, but let’s start off simple. How do
we get the Fweets? We start off by getting a reference to the Fweets
collection using the Collection function:
Collection('fweets')And we wrap that in the Documents function to get all of the
collection’s document references:
Documents(Collection('fweets'))We then Paginate over these references:
Paginate(Documents(Collection('fweets')))Paginate requires some explanation. Before calling
Paginate, we had a query that returned a hypothetical set of
data. Paginate actually materializes that data into pages of
entities that we can read. Fauna requires that we use this
Paginate function to protect us from writing inefficient queries
that retrieve every document from a collection, because in a database
built for massive scale, that collection could contain millions of
documents. Without the safeguard of Paginate, that could get very
expensive!
Let’s save this partial query in a plain JavaScript variable reference that we can continue to build on:
const references = Paginate(Documents(Collection('fweets')))So far, our query only returns a list of references to our Fweets. To
get the actual documents, we do exactly what we would do in JavaScript:
map over the list with an anonymous function. In FQL, a Lambda is
just an anonymous function.
const fweets = Map(
references,
Lambda(['ref'], Get(Var('ref')))
)This might seem verbose if you’re used to declarative query languages like SQL that declare what you want and let the database figure out how to get it. In contrast, FQL declares both what you want and how you want it, which makes it more procedural. Because you’re the one defining how you want your data, and not the query engine, the price and performance impact of your query is predictable. You can exactly determine how many reads this query costs without executing it, which is a significant advantage if your database contains a huge amount of data. So there might be a learning curve, but it’s well worth it financially and hassle it saves you. And once you learn how FQL works, you find that queries read just like regular code.
Let’s prepare our query to be extended easily by introducing Let.
Let allows us to bind variables and reuse them immediately in the
next variable binding, which allows you to structure your query more
elegantly:
const fweets = Map(
references,
Lambda(
['ref'],
Let(
{
fweet: Get(Var('ref'))
},
// Just return the fweet for now
Var('fweet')
)
)
)Now that we have this structure getting extra data is easy. So let’s get the author:
const fweets = Map(
references,
Lambda(
['ref'],
Let(
{
fweet: Get(Var('ref')),
author: Get(Select(['data', 'author'], Var('fweet')))
},
{ fweet: Var('fweet'), author: Var('author') }
)
)
)Although we did not write a join, we have just joined Users (the author) with the Fweets. Browse `src/fauna/queries/fweets.js` to view the final query and several more examples.
More in the code base
If you haven’t already, please open the code base for this Fwitter example app. You can find a plethora of well-commented examples we haven’t explored here. This section touches on a few files we think you should check out.
First, check out the `src/fauna/queries/fweets.js` file for examples of how to do complex matching and sorting with Fauna’s indexes (the indexes are created in `src/fauna/setup/fweets.js`).
We implemented three different access patterns to get Fweets by popularity and time, by handle, and by tag:
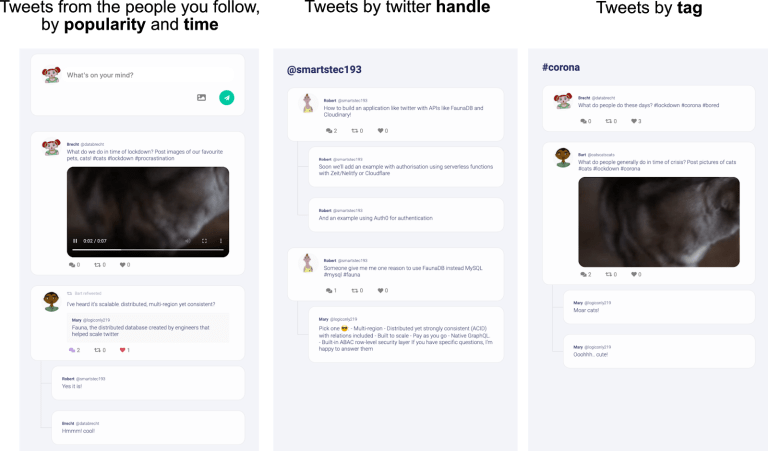
Getting Fweets by popularity and time is a particularly interesting access pattern because it actually sorts the Fweets by a sort of decaying popularity based on users’ interactions with each other.
Also, check out `src/fauna/queries/search.js`, where we’ve implemented autocomplete based on Fauna indexes and index bindings to search for authors and tags. Since Fauna can index over multiple collections, we can write one index that supports an autocomplete type of search on both Users and Tags.
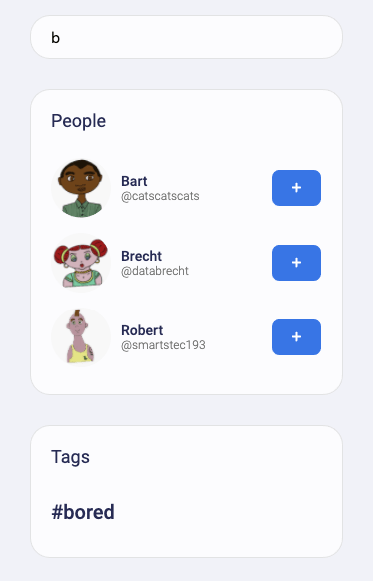
We’ve implemented these examples because the combination of flexible and powerful indexes with relations is rare for scalable distributed databases. Databases that lack relations and flexible indexes require you to know in advance how your data is going to be accessed, and you can run into problems when your business logic needs to change to accommodate your clients’ evolving use cases.
In Fauna, if you did not foresee a specific way that you’d like to access your data, no worries — just add another index! We have range indexes, term indexes, and composite indexes that can be specified whenever you want without having to code around eventual consistency.
Is this article helpful?
Tell Fauna how the article can be improved:
Visit Fauna's forums
or email docs@fauna.com
Thank you for your feedback!